Connection Pools in Java using Apache’s DBCP Library →
For most basic Java applications, such as school projects or one-off prototypes, having a simple database Connector class where individual connections are handled are enough to complete the assignment.
However, in a production enviornment, a server application will typically be multi-threaded, and thus, require multiple database connections asyncronously. For enviornments such as these, it’s best to let a libray handle the connection management.
Database connection without a connection pool
Let’s use a simple example of what a connection class to a database may look like:
//See https://github.com/ColbyLeclerc/blog-connection-pools/blob/master/src/main/java/database/Connector.java
package database;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class Connector {
public Connection getDMConnection() {
try {
Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");
} catch (ClassNotFoundException e) {
throw new RuntimeException("Cannot find the driver in the classpath!", e);
}
Connection conn = null;
try {
conn = DriverManager.getConnection("jdbc:sqlserver://SERVERIP:PORT;databaseName=DATABASE", "USER", "PASS");
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
}Very simply, we first check to ensure the appropriate driver is loaded, then we initialize the connection using the given credentials.
However there are a few things wrong with the above snippet, mainly the Connection object is handled outside the scope of the method. What happens if the caller doesn’t close the Connection object after use? The connection then stays open until the database server terminates the connection. Depending on the Database Management System (DBMS) and parameters, this behavior varies.
Furthermore, what if we had 5 threads call this method? Or even worse, what if a bug in our code creates 500 threads, each of which requesting a database connection? That would mean the program would make 500 calls to the method, opening and closing the connection each time, which is very inefficient, and could potentially spam the database server, leaving other application’s queries and connections to hang, or drop.
A properly configured connection pool can solve both of these problems.
What is a connection pool?
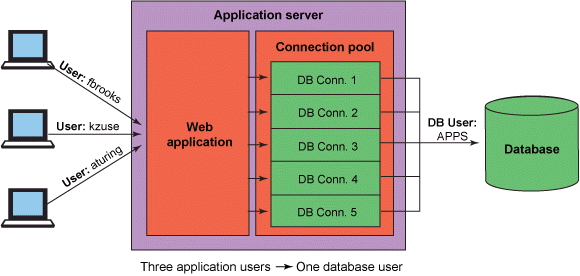
A connection pool is a cache of database connections maintained so that the connections can be reused when future requests to the database are required.
Depending on the configuration, a connection pool will open a predefined amount of connections for use. Once a connection is requested, the pool dedicates the specific connection to the requested process. Once the process closes the connection, the pool then places the connection back into the “pool” of available connections.
This system allows us to restrict the amount of opened connections, and from a design perspective, allows us to integrate a multi-threaded business solution more easily.
How do I implement a connection pool?
Most tools applicable for standard software development have already been written, tested, and packaged into a library. Connection pools are no different, thus, we’ll be looking at Apache Common’s DBCP Library
Here’s the code snippet, then we’ll discuss each part
//See https://github.com/ColbyLeclerc/blog-connection-pools/blob/master/src/main/java/database/DBCPDatabase.java
package database;
import org.apache.commons.dbcp2.BasicDataSource;
import java.sql.SQLException;
public class DBCPDatabase {
private static BasicDataSource dataSource;
//Insert log4j statement
public static BasicDataSource getDataSource() {
if (dataSource == null) {
BasicDataSource ds = new BasicDataSource();
ds.setUrl("jdbc:sqlserver://localhost;databaseName=testdba");
ds.setUsername("testdb");
ds.setPassword("W91gLUJWfRS3sg37");
ds.setDriverClassName("com.microsoft.sqlserver.jdbc.SQLServerDriver");
ds.setInitialSize(3);
ds.setMaxTotal(25);
ds.setMinIdle(0);
ds.setMaxIdle(8);
ds.setMaxOpenPreparedStatements(100);
dataSource = ds;
}
return dataSource;
}
public static void shutdown() {
if (dataSource != null){
try {
dataSource.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}Note: The above code snippets don’t represent best software engineering practices (for instance hard-coding the database username/password)
First off, we see the method signature and class variable are both static. Note the BasicDataSource is not a replacement for a Connection, but instead is a layer above. Below we’ll show an example of how to use it.
The JavaDocs for BasicDataSource class is rather extensive (found here). I’ll briefly explain the options above:
| Parameter | Description |
|---|---|
| setInitialSize | Sets the initial size of the connection pool |
| setMaxTotal | Sets the maximum total number of idle and borrows connections that can be active at the same time |
| setMinIdle | Sets the minimum number of idle connections in the pool |
| setMaxIdle | Sets the maximum number of connections that can remain idle in the pool |
| setMaxOpenPreparedStatements | Maximum amount of open prepared statements |
On startup, the connection pool’s size will be 3 connections (setInitialSize), then will grow to 25 active connections (setMaxTotal). Next, if there are no active requests, the connection pool will idle with a minimum of 0 connections (setMinIdle) and a maximum of 8 idle connections (setMaxIdle). Lastly, the max amount of open prepared statements is set at 100 (setMaxOpenPreparedStatements).
- Active Connection: a connection in-use by a process
- Idle Connection: a connection within the pool that is ready to be used
Lets look at an example of using the connection pool:
//See https://github.com/ColbyLeclerc/blog-connection-pools/blob/master/src/main/java/Main.java
import database.DBCPDatabase;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class Main {
public static void main(String[] args) {
//Note Java 8's 'try-catch' automatically closes the connection and statement via an internal 'finally' block
try (Connection conn = DBCPDatabase.getDataSource().getConnection();
PreparedStatement statement = conn.prepareStatement("UPDATE TestTable SET Username = 'new_username'")) {
statement.execute();
} catch (SQLException ex) {
ex.printStackTrace();
}
}
}From a usability perspective, the only difference between using a connection pool and directly calling for the Connection object (from our Connector class) is the extra ‘getDataSource()’ method call.
What if the max active connections limit (in our case, 25) is reached?
If all 25 active connections are in use, then the request is queued until a connection is released.
What happens when we close the connection? Do we still have to close connections?
By closing the connection retrieved from the BasicDataSource object, we let the connection pool know the connection is ready for reuse by another process. Closing the connection doesn’t actually close the connection, because we let the connection pool manage connections.
So how do we actually shutdown the connection pool?
Looking at the ‘shutdown()’ method in the second Gist, we can see when calling the ‘close()’ method on the DataSource, this actually closes the pool. You’ll want to call this during the shutdown event for your application.
Conclusion
With a connection pool, if the thread bug mentioned earlier attempted to start 500 threads, each requesting a connection, the connection pool would not allow for more than 25 total active connections. The 475 other connection requests would be sent into a queue on the application server layer, making for a happy DBA.